Home › Forums › Logical Invest Forum › Ranking Mismatch Using Modified Sharpe
- This topic has 3 replies, 2 voices, and was last updated 5 years, 3 months ago by
Alex @ Logical Invest.
- AuthorPosts
- 01/11/2021 at 11:27 am #81073
hppeng
ParticipantHi,
I’m trying to replicate the ranking system by QT. As the QT tutorial mentioned, ranking is done by:
“rd/sd^f” where1. rd is the mean of daily_return during the lookback period
2. sd is the stdev of the daily return during the lookback period
3. f is beween 0 and 10 for volatility attenuationI wrote a simple script to rank my list of stocks using the above math, trying to see if the ranking matches QT’s result. It ends up with totally different ranking.
Am I missing something? Is the math really the same as described above? Thanks.
01/12/2021 at 2:52 am #81077Alex @ Logical Invest
KeymasterHi HP,
while above indeed is in concept how the ranking works, you will find some caveats during the validation of your own model. These require some normalization before we can rank by the “modified sharpe”. We do not publish these steps in detail – just to keep the fun factor of reproducing the model, the same as we love the thrive when replicating other models.
But QT gives you all you need, just have a close look at the values in the different cols in the “ranking report”, there is all you need for a rainy weekend. Several users have successfully reverse engineered the model, which as great as we used their input to further improve it.
01/12/2021 at 10:33 am #81081ParticipantAlexander,
Would appreciate it if you can shed some lights on “normalization”. Any papers in the internet you can point me to?
Thanks.
01/13/2021 at 3:03 am #81085KeymasterAs said before, during your exploration of the ranking process you will see the necessity for normalizing certain computations in order to make the ranking work as expected.
It is important for us to be transparent in how the methodology works – and most importantly: That it works! But we’re not publishing the computation in detail, at the end this is not an “open source” project – and would it make no fun to try to replicate.
You will probably find even a smarter way, just give it a try. If you want to mimic exactly our process look at the values in the ranking log, there is all you need:
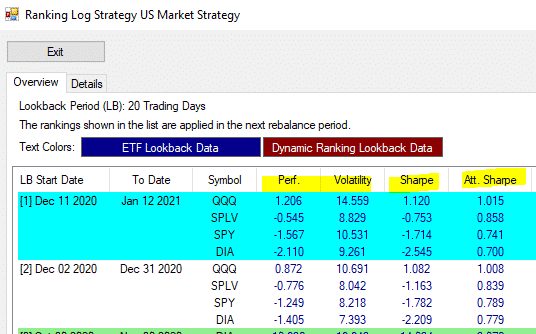
- AuthorPosts
- You must be logged in to reply to this topic.